

by Ray Bernard PSP, CHS-III
May-Jun 2019
This question about video analytics touches on an area where Deep Learning is making a real impact: security video analytics.
Q: I keep reading that today’s video analytics are much more accurate – such as 95 percent versus 75 percent – than they were just five years ago. Has there been a change in the related science?
A: Video analytics has significantly improved due impacts of two categories of Artificial Intelligence (AI): Machine Learning and Deep Learning.
Artificial Intelligence (AI) is an area of computer science that is more than 50 years old and that is now on the steep upward end of its exponential growth curve due to the billions of dollars of annual R&D investment and the massive computing capabilities that can be applied to it. One area of AI advancement is deep learning, which is a category of machine learning, which is the science of getting computers to perform actions without specifically being programmed to do so.
For example, machine learning software for email spam filtering would be “trained” on recognizing spam by being fed thousands of emails labeled either as spam or not spam, and the software would analyze each email and determine from those examples how to identify spam.
Deep learning is a type of machine learning that involves artificial neural networks, whose designs are inspired by the way that scientists believe the brain works. A neural network is built from pieces of software called “nodes”, which are organized into layers. Each layer performs a step in the processing, passing along its results from one layer to the next. Deep learning software typically contains three parts: an input layer, hidden layers, and an output layer. Hidden layers are so named because there are no connections to them from the neural network’s input and output interfaces.
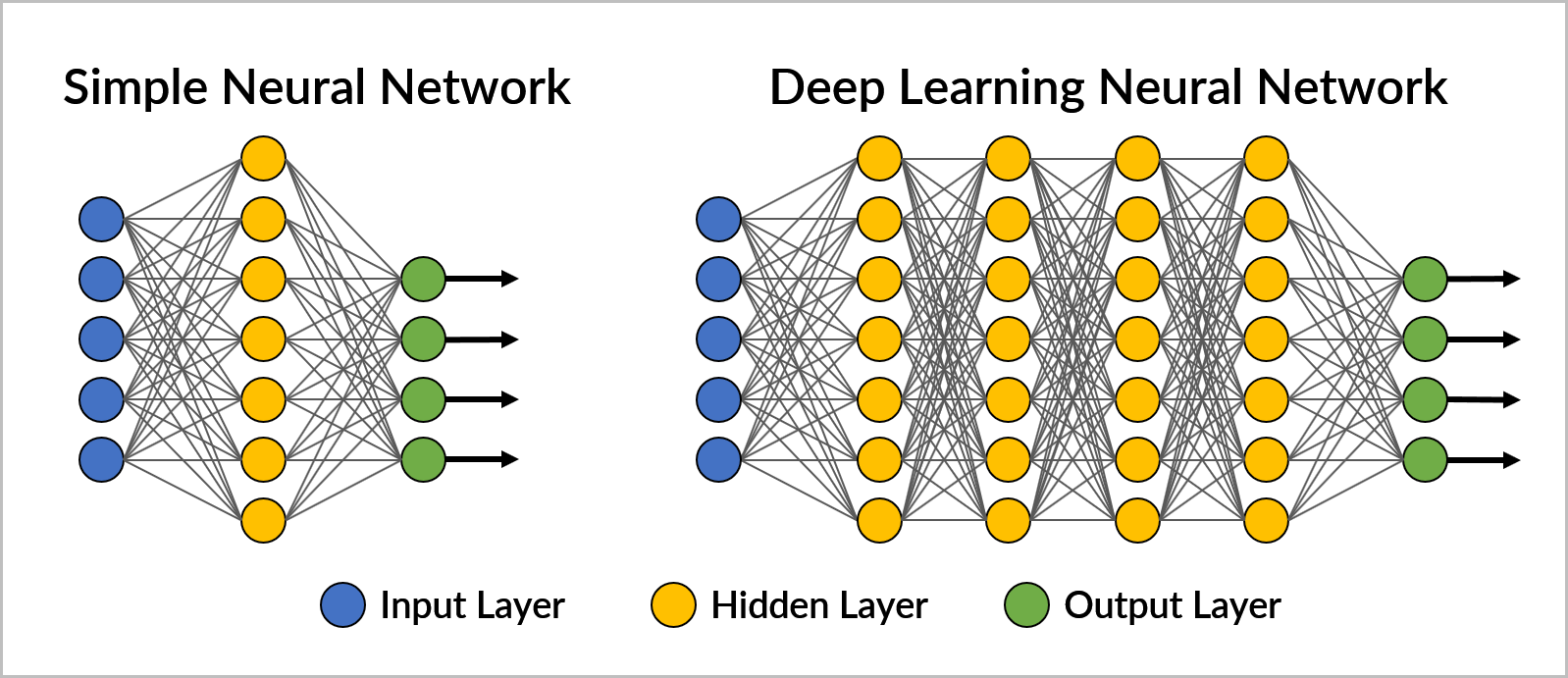
For example, an object detection neural network may have the following layers: input layer (contains a still image of a scene), hidden layers (detect moving object, detect object parts, classify object parts, classify object) output layer (provide information on an object).
For bicycle detection, let’s say that the layer for “detected object parts” identifies wheels, handlebars, frame and cyclist. The layer for “classify object parts” differentiates between a bicycle wheel and a motorcycle wheel. The layer for “classify object” concludes it’s a bicycle, not a motorcycle.
How many hidden layers there are depends upon how challenging the various steps to object recognition are and how much software is required for each step. What if a cyclist’s backpack must be detected? What about a second rider on the bicycle? Do colors matter? Does object speed matter?
The term “deep” refers to neural network software that has many hidden layers, the number of layers determining the depth. A simple neural network has one or two hidden layers between the input and output layers; three or more hidden layers makes it a deep learning neural network.
The Value of Deep Learning
One purpose of machine learning is to perform information processing better, faster and/or cheaper than a human. Being better relates not just to task accuracy, but to bigger picture aspects as well. Can a robot perform inspections as well as a human in areas where environmental hazards pose a human life safety risk? In such a case, being close to human performance ultimately has a benefit of saving lives.
Machine Learning Increases Performance
I researched video analytics advances in 2016 and wrote a technical paper for the Security Industry Association titled, “The State of Security Video Analytics” (https://bit.ly/advanced-security-video-analytics). This paper explains, with illustrations, how machine-learning video analytics software creates data models of the cameras’ fields of view, and updates them in real time, building on what it has learned. Recording based on motion detection, for example, has always been a challenge for outdoor cameras. It required manually creating motion masks in the configuration of the camera or video management system to block out the parts of the field of view where clouds or trees would create irrelevant motion.
This approach doesn’t work if the moving parts of the scene are behind moving people or vehicles because those are areas of interest and masking them off defeats the purpose of the camera. Motion masks can’t address rain or snow. However, the new generation of smart analytics can distinguish between clouds, trees, and relevant foreground motion, using machine learning to do so no motion masks or special configuration is required. The analytics are self-configuring.
Deep Learning Tops All Previous Performance
In 2018, breakthroughs in deep learning began appearing in security video analytics, with accuracy rates between 95 percent and 98 percent. Much of the information available on the web regarding deep learning almost immediately does a deep dive into “neural networks.”
These new analytics are working so well for most applications, not only are vendors willing to talk about their accuracy rates and success stories, but they are also willing to discuss the applications and conditions where the accuracy rates fall below 95 percent. One explanation is, that level of accuracy is not always needed. Another is that security video analytics had an early disappointing history and the analytics vendors don’t want that to happen again.